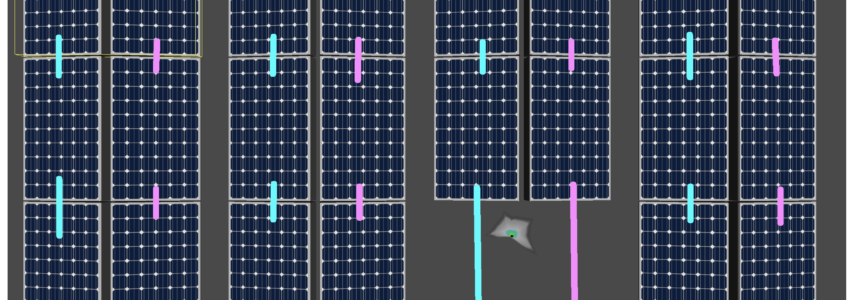
Solar System – Electrical Design
When we bought our house, one of the criteria was a photovoltaic system on the roof. In 2018, we finally found our dream home, with a flat roof with no shade — it was perfect! In this series of posts, I will describe the design and installation of our system. It is a 9.4kW system… Continue Reading Solar System – Electrical Design